Vaidotas (Vaidas) Šimkus
I'm a Senior ML researcher and engineer who values simple, scalable solutions to hard problems affecting innovation. At Orbital, I build atomistic foundation models and post-train LLMs for accelerated materials discovery and hardware engineering, applied to carbon capture and data center cooling. I'm also the core maintainer of Orb, our open-source SoTA forcefield model.
I did my PhD in Machine Learning at the University of Edinburgh, advised by Michael Gutmann, focusing on probabilistic modelling with missing data. I also hold a BEng in Software Engineering from the University of Southampton.

Papers


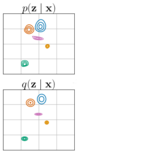
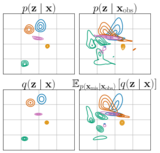
Improving Variational Autoencoder Estimation from Incomplete Data with Mixture Variational Families
Transactions on Machine Learning Research (TMLR), 2024
url / bib / arxiv / code / poster / dmlr-at-iclr2024
We show that missing data increases the complexity of the posterior distribution of the latent variables in VAEs. To mitigate the increased posterior complexity we introduce two strategies based on (i) finite and (ii) imputation-based variational-mixtures.
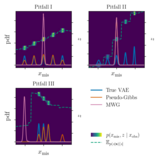
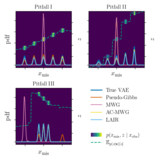
Conditional Sampling of Variational Autoencoders via Iterated Approximate Ancestral Sampling
Transactions on Machine Learning Research (TMLR), 2023
url / bib / arxiv / code
We link a structured latent space in VAEs, a commonly desired property, to poor conditional sampling performance of Metropolis-within-Gibbs (MWG). To mitigate the issues of MWG we introduce two original methods for conditional sampling of VAEs: AC-MWG and LAIR.
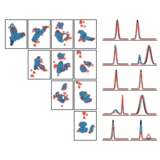
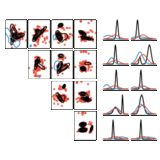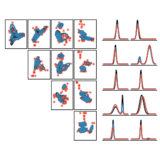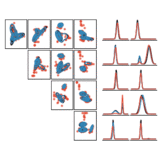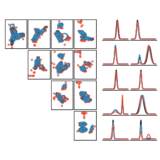
Variational Gibbs Inference for Statistical Model Estimation from Incomplete Data
Journal of Machine Learning Research (JMLR), 2023
url / bib / arxiv / code / poster / slides / jmlr-to-neurips2023 / demo
We propose a new method for statistical model estimation from incomplete data, called variational Gibbs inference (VGI). Whilst being general-pupose, the proposed method outperforms existing VAE and normalising flow specific methods.
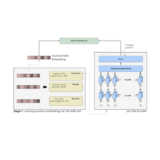
Learning Job Titles Similarity from Noisy Skill Labels
FEAST workshop at ECML-PKDD, 2022
url / bib / arxiv / dataset
We propose an unsupervised representation learning method for a job title similarity model using noisy skill labels. We show that it is highly effective for tasks such as text ranking and job normalization.